

Justin Sullivan/Getty Images News
Moving On All Fronts
Just a simple diagram of what was announced (Nvidia presentation)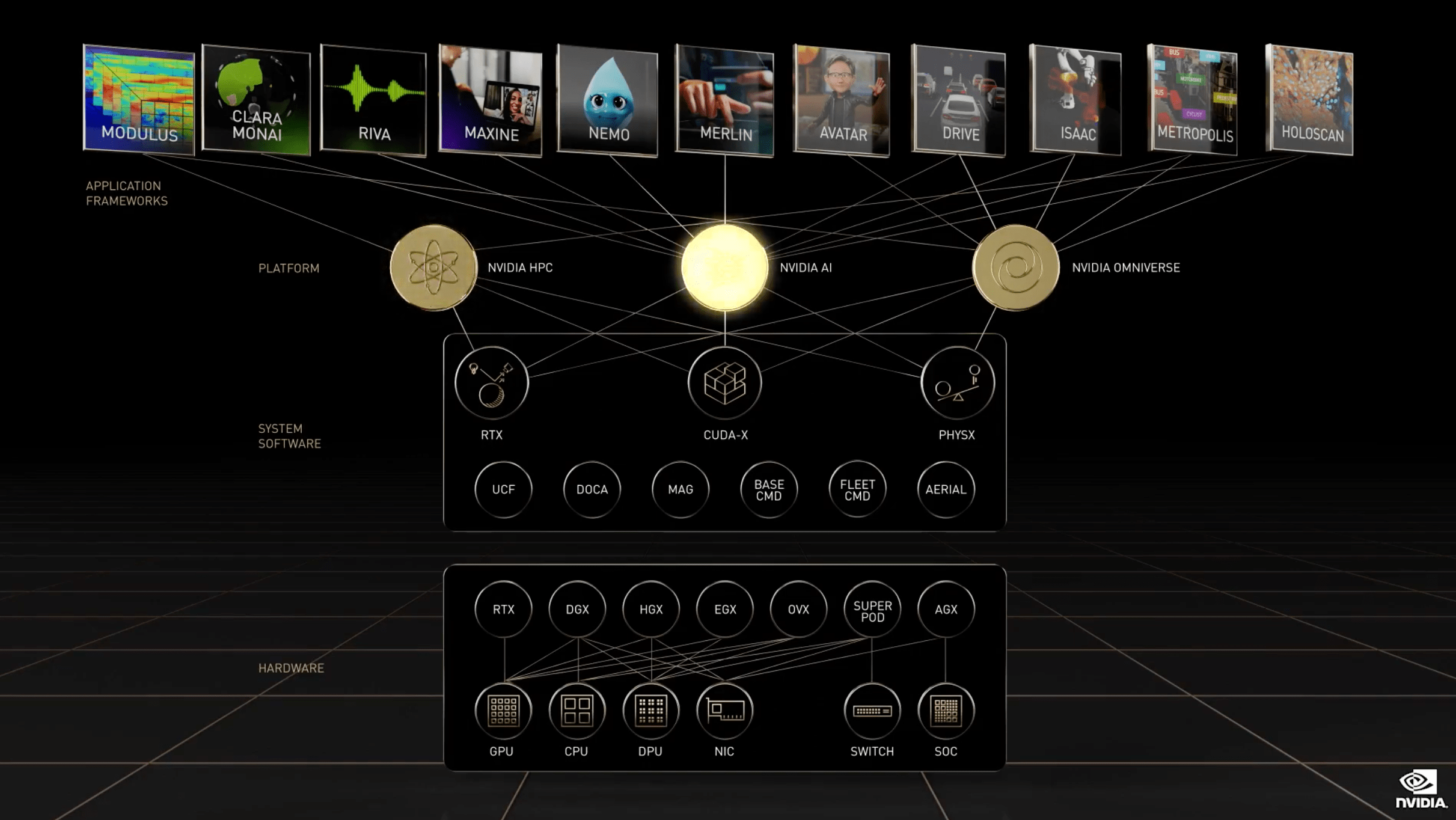
NVIDIA (NASDAQ:NVDA) CEO Jensen Huang is someone who can focus on a lot of things at once, but it made for a messy keynote presentation last week at their annual developers conference. The “fast recap” at the end took over 6 minutes. You see that graphic above, laying out the whole Nvidia platform for data center AI. That was the summary diagram for the presentation, Huang touched on almost all of it, and the whole thing lacked organization.
I am here to help him with that. Here’s what is happening:
- Nvidia already had a huge lead on everyone in GPUs and the software that runs them for high performance compute. GPUs are increasingly used for heavy duty compute in data centers and crypto mining.
- So they decided to begin there, and build an entire one-stop shop of hardware and software around it to power all the AI and heavy compute that is going to be running in data centers in the future.
What’s happening here is a simple vertical integration story, behind all that complexity. My view is that they are executing exceptionally well so far, and look to have a pipeline of compelling products coming.
But Nvidia stock remains priced for perfection.
Grace and Hopper
Grace Hopper in 1984 (US Navy)
Pictured above at 78 and looking every bit the badass she was, Grace Hopper retired a Rear Admiral in the US Navy, and was one of the premiere early computer programmers. She was a key contributor in several early programming languages including COBOL, still in wide use today, like in Bloomberg Terminal.
Grace and Hopper are the names Nvidia has given to the hardware that undergirds their AI software – the central processing unit or CPU, and the graphics processing unit, or GPU. Grace was the reason they wanted to buy ARM — so they could control the ARM roadmap to focus it on high performance computing. But they are still going ahead as an ARM licensee.
The 144-core Grace chip. (Nvidia presentation)
So thar she blows. They are essentially making a similar CPU design to what Apple (AAPL) just introduced with the M1 Ultra, but with very important differences. The big similarity is that it is two identical chip dies connected together via a very high speed interface. In Nvidia’s case, they call it NVLink, and this is a key part of the whole thing, because it links more than just those two dies.
The big difference is that Apple only uses a small portion of the die surface for the CPU, whereas those Nvidia dies are all ARM CPU, 72 cores on each die. This looks like it will blow away anything Intel (INTC) or AMD (AMD) will have when it is released in 2023, especially factoring in power consumption, a key part of data center OpEx. It is still a long way off, but I think this will instantly be the best data center CPU, ARM or x86.
For Nvidia’s AI stack, the Grace CPU will sit at the base and act as the ringmaster for many, many circuses running on Hopper. Hopper is the name for Nvidia’s new GPUs, their core product from which they are building out. While we still call them “graphics processing units,” they do a lot more these days on heavy duty compute that uses floating point math like AI and crypto mining.
So these new GPUs will of course also be popular with gamers and crypto miners, but Nvidia was pitching them as the workhorses of the AI revolution last week. These will show significant scalable performance improvements over the current generation, Ampere. That scalable part is very important, because it means as problems get bigger, you can keep throwing more GPUs at it.
Hopper improvements over Ampere. H100 is Hopper and A100 is Ampere. (Nvidia presentation)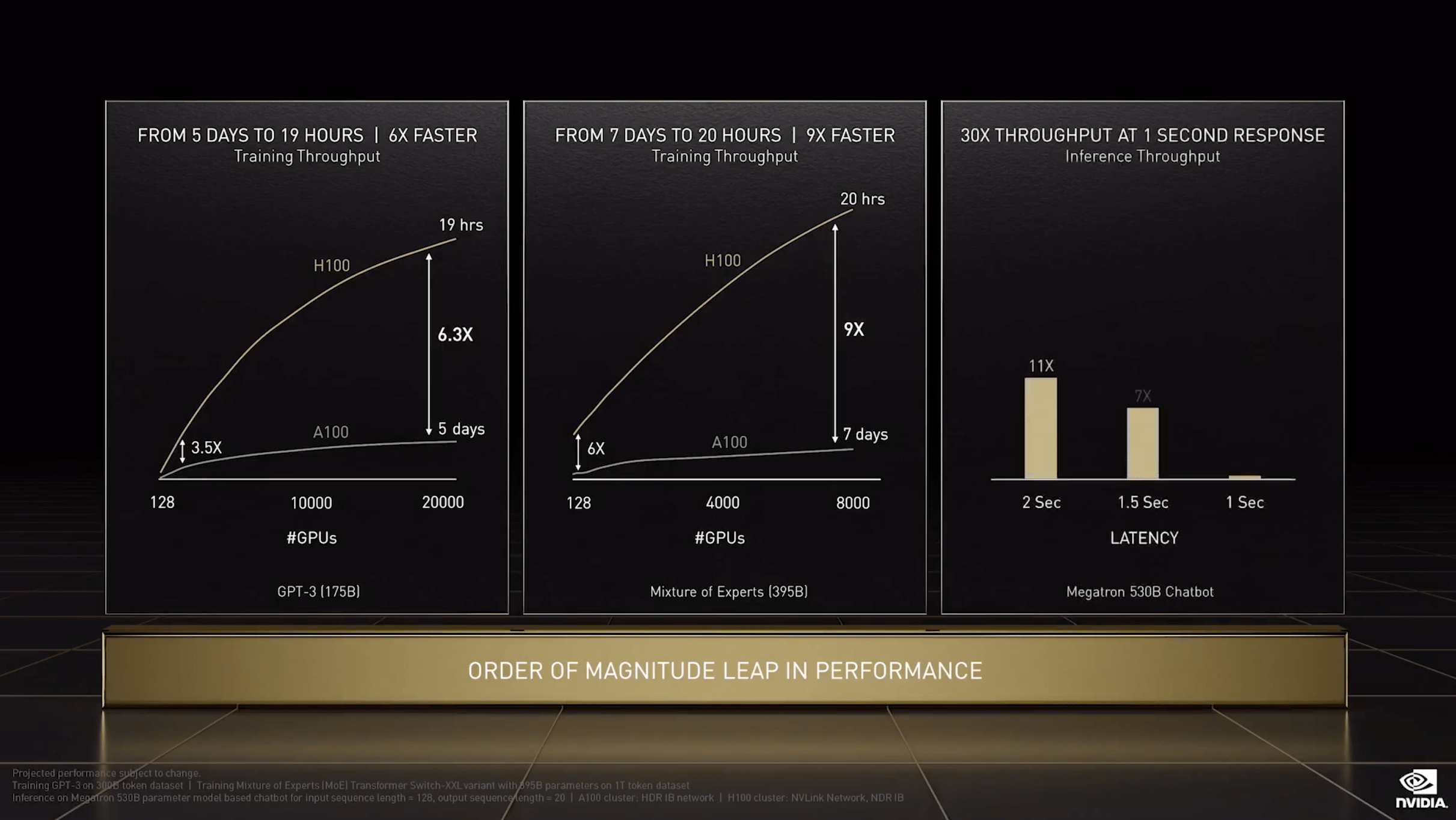
Grace and Hopper are sewn together by NVLink, Nvidia’s very high speed connection. In fact, there are multiple ways to configure a server using all that NVLink bandwidth, from a single Grace and Hopper, to 2 Graces and 8 Hoppers.
Grace-Hopper configurations (Nvidia presentation)
All of these chips will be built at TSM (TSM).
So that is the first two legs of Nvidia’s hardware stool. The Grace CPU is a very high performance and low power consumption data center CPU that runs the show. The new Hopper GPUs do all the heavy lifting on these giant AI models and data sets. But in all those setups you see in the last graphic, there is also the third leg of the stool, the CX7. It is Nvidia’s network interface, part of Spectrum, their whole data center networking package.
Spectrum: The Third Leg of The Stool
The data sets and models for AI keep getting exponentially larger, which puts a strain on CPU and GPU throughput to begin with and that’s what Grace and Hopper are for. But the other problem is moving all this data around the data center, especially when storage is on the network. This leads to two problems:
- Network and storage bandwidth are the biggest bottlenecks.
- The CPU spends too much of its time moving data around, slowing it down for the other important tasks it is running.
Networks bandwidth will remain a bottleneck, because it will always be exceeded by the bandwidth inside the server. But the faster it goes, with the least latency and jitter saves time, which is the key scarce resource when processing giant AI models and datasets. There are three parts to their network infrastructure, all running at 400Gb ethernet or InfiniBand, right now the fastest there is:
- The CX7 network interface card, which is in the server. As far as I know, no one else has a 400Gb on-server interface. Intel is still pitching 100Gb cards. If you scroll back up to the Grace-Hopper configurations graphic, you will see each Hopper gets its own network interface, which makes the whole setup super-fast and removes bottlenecks inside the server.
- The Spectrum 4 ethernet switch, which is a standard switch, but with a mind blowing 51Tb of total bandwidth, and future-proofed to be configurable up to 800Gb ethernet, the next step up.
- The bad boy of the group that really differentiates Nvidia’s network package is the Bluefield data processing units that came over with Mellanox. These units are supercharged network interface cards that offload all the data management tasks from the CPU onto a dedicated chip that does nothing else. These chips can manage network or attached local storage, handle encrypted data, and provide other security services. All of it is configured by Nvidia software.
All this, again, will be connected at the server level by NVLink.
NVLink (Nvidia presentation)
Not even Cisco (CSCO) has a data center package like this. The one place Nvidia is behind on is silicon photonics, which is a newish network interface where Intel is the leader.
All of these chips will also be built at TSM.
So that’s the three legs of the hardware stack that all the software sits on top of. Let’s talk about that, because it is going to be a big driver of hardware sales and licensing revenue.
Omniverse
I am going to focus mostly on Omniverse here, which is basically Nvidia trying to recreate the physical world in digital form. All of it.
But some of the other AI software Huang was pitching:
- Triton: this massive model undergirds efforts for recommendation engines, chatbots, and other “inferential” AIs.
- Riva: speech recognition and generated speech.
- Maxine: this is AI-aided video conferencing, and it is actually more interesting than it sounds. Maxine can, for example, keep your eyes on camera even if you are looking down at a script. It can also translate to multiple languages on the fly, and make your mouth (almost) look like you are speaking that language.
- Nemo: for training very large language models
There was a lot more, and this is all sort of first-generation commercial AI: stuff we have now, however imperfect. Omniverse is about the next generation of AI that will be out in the real world doing stuff like automating factories, warehouses, transportation and drug discovery.
The basic idea is to create a digital twin of everything in the world, including you.
Avatar Jensen (Nvidia presentation)
Unlike what Facebook (FB) showed off, the avatar as a representation of the person in a digital world, Nvidia’s Avatar project aims at making a 3D digital clone that can move and talk on its own, a digital robot. They still have a long way to go — the voice is robotic, “natural language” is not that natural, and the gestures are off — but they are pretty far along compared to anyone else in making digital robots.
But it’s the entire physical world and every object in it they want to recreate digitally to support this next generation of AI work:
Twinning the world (Nvidia presentation)
When they first announced Omniverse last year, it was during peak metaverse hype, so that’s what they leaned into for that presentation. But last week, they were more focused on robotics and drug discovery as the two near-term applications for all this hardware and software. Robotics was this big star, and it includes vehicles of all types, sizes and applications, physical robots and digital ones like the Jensen Avatar. The applications range from self-driving to factory/warehouse automation to customer service.
Drug discovery is very interesting to me. With models of real world physics, chemistry and biology, molecules can be rapidly developed and tested in a digital world, and promising ones real-world developed in a much shorter time frame. All of the major pharma companies are working on this, and there are a large number of startups getting funding lately.
Summing Up
- Nvidia presented a complete stack of hardware and software for AI and other heavy duty data center compute.
- If it comes out on time and as promised, Grace will likely be the best data center CPU available, especially when taking power consumption and operating costs into account.
- Hopper is another big step forward in their already industry-leading GPUs, which do the heavy-duty compute. They are highly scalable, which is very important.
- Their Spectrum networking package provides a complete 400Gb solution, both in the server and on the network. The biggest differentiator will be the Bluefield data processing units. Nvidia does, however, lack silicon photonics.
- On top of the three-legged stool of hardware sits all their AI software, models and data sets. They are building out a very nice suite as a complete package.
- The most ambitious project is Omniverse: recreating the entire physical world digitally. This will be the basis of lots of AI work.
The biggest “but” to all this is that Nvidia may be doing the thing they frequently do, which is getting a little far out ahead of a trend. In an interview with Ben Thompson after the presentation, Huang was discussing the development of programmable shaders, a key Nvidia innovation. At the end of telling the tale, he said, “The punishment afterwards was what we didn’t expect.”
When asked to elaborate by Thompson:
Well, the punishment is all of a sudden, all the things that we expected about programmability and the overhead of unnecessary functionality because the current games don’t need it, you created something for the future, which means that the current applications don’t benefit. Until you have new applications, your chip is just too expensive and the market is competitive.
Translation: we got out over our skis. I view Jensen Huang as one of the best tech CEOs, and also one of the most interesting. But the thing that makes him so good — his ability to see where things are going and what solutions are needed to get there — is also the thing that gets Nvidia out over their skis sometimes.
I don’t think this is one of those times, but aside from execution risk, this is the most prominent risk to this vertical integration play.
Trading Nvidia
Nvidia has been very frustrating to me. I am a big fan of their prospects, but I am not the only one:
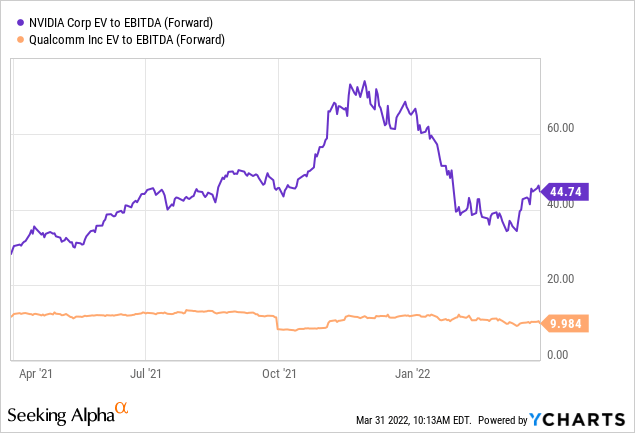
Those are two semi designers whom I think have great prospects. Both have excellent current businesses that are growing fast.
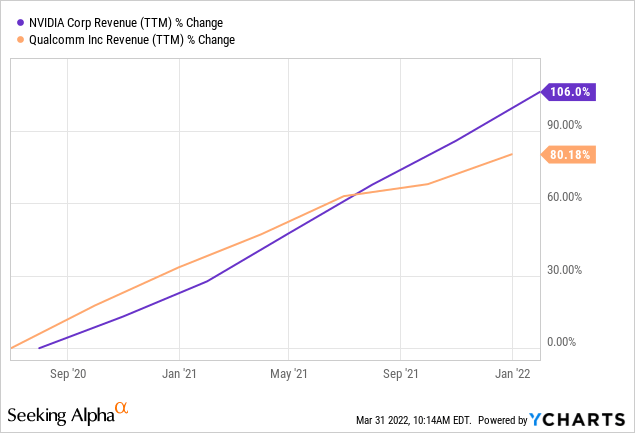
I would put a higher multiple on Nvidia than QUALCOMM (QCOM) but not 4 times higher.
So I am sitting here still with only a small position, wanting it to be more, but balking at the price. I thought the inevitable end of the ARM deal would provide a buying opportunity, and in a way it did, but the stock never got cheap.
So I am going to wait some more. Nvidia is again priced for perfection, and no one is perfect.
A Note on the ARM Deal
This was always going to be a very high climb, close to impossible, and it is the worst example yet of Jensen Huang getting out over his skis. It was entirely predictable that this deal would never go through.
Why they would want to pay a premium for ARM is understandable. It’s important for Nvidia’s future plans that ARM focus development on high performance computing, and less on smartphone and IoT chips. The only way he could guarantee that was by buying the company. He was going to pay mostly with shares trading at about a century of trailing free cash flow, so why not?
The reason was that there were regulators in 4 places, US, UK, EU and China, who had leverage, and all 4 were almost assuredly going to say no to this deal.
- US and EU: ARM had never before competed with their customers. Their business model is to be the Switzerland of CPU IP. Now they would be competing with customers, and they were all unhappy with this, especially among the smartphone and IoT designers, who saw the writing on the wall for them.
- UK: ARM is the jewel of UK tech, and there was a lot of nationalist fervor over this on the heels of Brexit. It began the day of the announcement.
- China: They would never let such important IP go to a US company, especially one run by a Taiwanese immigrant to the US if they could avoid it.
I can’t believe no one told Jensen Huang these very obvious things, and that he chose to ignore it on the small chance they could snag ARM.
From that Ben Thompson interview:
JH: [I]t is a singular asset. You’ll never find another ARM asset again. It’s a once-in-a-lifetime thing that gets built, and another one won’t get built… [W]e felt and we believed and it’s true that their primary focus on mobile was fantastic, but their future focus ought to be the data center. But the data center market is so much smaller in units compared to mobile devices, that the economic motivation for wanting to focus on servers may be questionable. If we own the singular asset that’s up for sale, and we were to motivate them, encourage them, direct them in addition to continuing to work on mobile, also work on data centers, it would create another alternative CPU that can be shaped into all kinds of interesting computers. Within our ownership, we would be able to channel them much more purposefully into the world’s data centers.
Well, in the last two years, the two companies spent a lot of time together, not in working together, but in seeing the future together. And we’ve succeeded, I think, and they naturally also were starting to feel that way, that the future of data centers is a real opportunity for them, and if you look at the ARM roadmap since two years ago, the single threaded performance roadmap of ARM has improved tremendously. So irrespective of the outcome, I think the time that we had spent with them has been phenomenally helpful for the whole industry for us.
So the breakup fee was a strategy consulting fee is basically how it turned out.
JH: Well, you know what? We can always go make more money. It was worth a try.
No, it wasn’t “worth a try.” Thompson is letting him off the hook here. The breakup penalty was $1.25 billion, not a “strategy consulting fee.” They could have paid ARM a few million for the same consultations. Even bigger than the direct costs are the opportunity costs. They spent over a year operating under the illusion that some of the best ARM chip designers in the world would become Nvidia employees this month. They could have used that time and $1.25 billion to do their own hiring. They could have, for example, done what Apple did years ago, and started making their own custom ARM core designs, so they would not be so dependent on the ARM roadmap. We see the benefits to Apple from that decision year after year.
Moreover, as the rest of this article proves, they did not need to own ARM. It is Huang’s worst unforced error yet, and frankly that he doesn’t seem to realize it worries me a bit.
Be the first to comment